Tree in Rdbms
邻接表
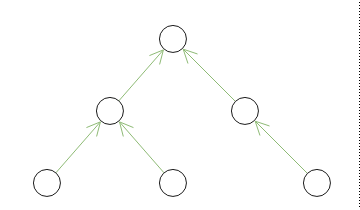
每个节点存储父节点
| code | pid | name |
|---|---|---|
| 1 | NULL | TOP |
| 2 | 1 | SEC |
| 3 | 1 | SEC_2 |
查询子节点:递归
获取到root的路径:递归
检查两个节点关系:递归
优点:
- 数据结构简单
- 增删改简单
缺点:
- 查询复杂
Subsets
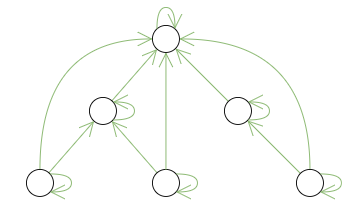
表保存所有的父类依赖关系
缺点:
数据冗余
查询复杂
Nested sets
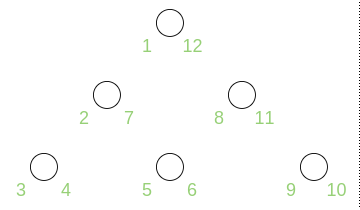
存储树的前序遍历,
优点:查询不使用递归
缺点:插入或修改时,整棵树都要进行编辑。可以使用较大间隔来优化
Materialized paths
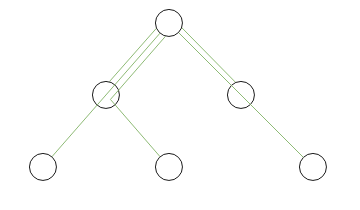
每个节点存储到根节点的路径。
获取子树使用like
SELECT * FROM goods_category WHERE path LIKE '1.1%' ORDER BY path
获取父类:
SELECT * FROM goods_category WHERE '1.1.3' LIKE path||'%' ORDER BY path
检查后代:
SELECT CASE
WHEN exists(SELECT 1 FROM goods_category AS gc1, goods_category AS gc2
WHERE gc1.name = 'Construction Material/Fixtures'
AND gc2.name = 'Cement'
AND gc2.path LIKE gc1.path||'%')
THEN 'true'
ELSE 'false'
END
也可以对每个层级使用独立的列,这会消除 like
优点: 数据直观,查询方便
缺点:数据插入移动删除复杂,数据深度受路径存储长度限制
总结
只有 Adjacency list 避免了冗余,单查询数据复杂,需要递归。
排序树,物化路径 查询可以避免